
Helix Tutorial: Cloud Support
There are emerging cases to use Helix in a cloud environment, especially in those well-known public cloud, e.g. Azure, AWS, GCP, etc. Compared to previous on premise use cases, Helix has faced both challenges and opportunities in providing cloud related support.
As a first step, Helix implemented the support for participant auto registration in a cloud environment, which leverages the common feature of public cloud and facilitates Helix users when they need to create a cluster and register the participants to the cluster.
After a Helix cluster is created, there are two ways to add instances (or participants, we will use them interchangeably in this tutorial) to the cluster. One is manual add, where users call their own scripts to add instance config to the cluster for each participant; and the other is auto join, where users set the auto join config of the cluster to be true, and each participant populates its own hostname, port number, and other information in instance config during connection. However, in an on premise environment, the auto join only works perfectly when users use Helix in a non rack-aware environment, meaning there is no fault domain concept. For a rack-aware environment, users still need to manually input the domain information to the instance config as it is hard for each participant to get its own fault domain information. Considering most users would use Helix in a rack-aware environment, it means manual work is still required.
In a cloud environment, there is a good opportunity to achieve full automation as public cloud providers give domain information to each individual instance through a metadata endpoint. All of the above mentioned public cloud providers use a unique non-routable IP address (169.254.169.254) for this purpose. It can be accessed only from within the instance to retrieve the instance metadata information, which you can use to configure or manage the running instance.
More specifically, in AWS, Azure, and GCP, the query to the fixed IP address http://169.254.169.254/ inside each instance will return its metadata information that contains domain information. In AWS, the field is named as “placement”; in Azure, the field is named as “PlatformUpdateDomain”; and in GCP, the field is named as “zone”. It is usually just an integer denoting which fault domain the instance belongs to. This particular feature of public cloud is leveraged by Helix in cluster creation and partition registration process.
What Helix Provides for Cloud Environment
- Provide definition of Helix cloud configs at cluster level and participant level
- Provide enhanced REST and Java APIs for cluster creation and cloud config update
- Provide generic interface for fetching and parsing cloud instance information
- Provide the implementation of Azure cloud instance information processor
- Provide the implementation of participant auto registration logic
How to Use Cloud Support
First of all, you need to make sure that your environment is indeed a cloud environment. Otherwise, all the assumptions in this support will not hold. Then depending on what kind of cloud environment you are in, you will need to perform some or all of the following steps.
Define Cloud config at Cluster Level
Helix provides cloud configs at two different levels, one is at cluster level, and the other is at participant level. We describe them separately.
At cluster level, we have a new Znode called CloudConfig. It has a few fields that store the relatively static cloud information for the whole cluster. Similar to other existing configs, Helix provides cloud config builder, validation, get/set functions. As the following table shows, the first two fields are required, and the last three fields are optional.
CLOUD_ENABLED must be set to true if the user would like to use Helix cloud support. CLOUD_PROVIDER is the type of the cloud environment. Besides the few well-known public cloud providers, the user can also define his/her cloud environment as “CUSTOMIZED”. CLOUD_ID is an optional field. It can be used to record any specific metadata information the user would like to record, e.g. the ID for the particular cluster inside a cloud environment, etc. If the user chooses to use the provider that already has default implementations in Helix, e.g., Azure, he does not need to provide the last two fields, as Helix already provides the default value for these two fields in system property, which is considered as a bundle with Azure implementation that would be discussed later. If the user uses customized providers, or chooses some other cloud environment that has not been implemented in Helix yet, the user needs to provide the last two fields and/or CLOUD_ID depending on his/her usage.
| Field | Meaning |
|---|---|
| CLOUD_ENABLED | determine whether the cluster is inside cloud environment and use Helix cloud support |
| CLOUD_PROVIDER | denote what kind of cloud environment the cluster is in, e.g. Azure, AWS, GCP, or CUSTOMIZED |
| CLOUD_ID | the specific id in cloud environment that belongs to this cluster |
| CLOUD_INFO_SOURCE | the source for retrieving the cloud information. |
| CLOUD_INFO_PROCESSOR_NAME | the name of the function that processes the fetching and parsing of cloud information |
Users could use either REST API or Java API to set these configs.
REST API Examples
Helix enhanced current cluster creation REST API as well as Java API with extra fields that represent cloud related input. For example, in the following modified createCluster API, addCloudConfig is a Boolean value denotes whether to create with cloud config, and the cloudConfigManifest is the cloud config string, which will be converted to a Znode record.
@PUT
@Path("{clusterId}")
public Response createCluster(@PathParam("clusterId") String clusterId, @DefaultValue("false") @QueryParam("recreate") String recreate,
@DefaultValue("false") @QueryParam("addCloudConfig") String addCloudConfig, String cloudConfigManifest)
Besides the enhanced cluster creation API, Helix also provides a set of cloud specific APIs in Java and REST that handles the get/add/update of cloud config.
- Create cluster and add meanwhile cloud config related information to ZK.
$ curl -X PUT -H "Content-Type: application/json" http://localhost:1234/admin/v2/clusters/myCluster?addCloudConfig=true -d '
{
"simpleFields" :
{
"CLOUD_ENABLED" : "true",
"CLOUD_PROVIDER": "AWS",
"CLOUD_ID" : "12345"
"CLOUD_INFO_SOURCE": {"http://169.254.169.254/"}
"CLOUD_INFO_PROCESSOR_NAME": "AWSCloudInformationProcesser"
}
}'
- Add cloud config to an existing cluster
$ curl -X PUT -H "Content-Type: application/json" http://localhost:1234/admin/v2/clusters/myCluster/cloudconfig -d '
{
"simpleFields" :
{
"CLOUD_ENABLED" : "true",
"CLOUD_PROVIDER": "AWS",
"CLOUD_ID" : "12345"
"CLOUD_INFO_SOURCE": {"http://169.254.169.254/"}
"CLOUD_INFO_PROCESSOR_NAME": "AWSCloudInformationProcesser"
}
}'
- Delete the cloud config of a cluster
$ curl -X DELETE http://localhost:1234/admin/v2/clusters/myCluster/cloudconfig
- Get the cloud config of a cluster
$ curl -X GET http://localhost:1234/admin/v2/clusters/myCluster/cloudconfig
- Update the cloud config of a cluster
$ curl -X POST -H "Content-Type: application/json" http://localhost:1234/admin/v2/clusters/myCluster/cloudconfig?command=update -d '
{
"simpleFields" : {
"CLOUD_ID" : "12345"
}
}'
- Delete some of the fields in the cloud config
$ curl -X POST -H "Content-Type: application/json" http://localhost:1234/admin/v2/clusters/myCluster/cloudconfig?command=delete -d '
{
"simpleFields" : {
"CLOUD_ID" : "12345"
}
}'
Define Cloud Configs at Participant Level
At participant level, Helix allows users to provide detailed cloud properties, which is more related to the participant’s actions. For default value, Helix provides Azure cloud properties, including not only the default cluster level config values for Azure, like CLOUD_INFO_SOURCE and CLOUD_INFO_PROCESSOR_NAME, but also some participant specific values, such as http timeout when querying AIMS (Azure Instance Metadata Service) in Azure, max retry times, etc.
cloud_info_source=http://169.254.169.254/metadata/instance?api-version=2019-06-04
cloud_info_processor_name=AzureCloudInstanceInformationProcessor
cloud_max_retry=5
connection_timeout_ms=5000
request_timeout_ms=5000
If users would like to use their customized config for participants, they can input the specific properties through Helix Manager Property when composing Zk Helix Manager, which is passed into participants. Helix Manager Property includes Helix Cloud Property which includes commonly used cloud properties and also any kind of user defined cloud properties.
public ZKHelixManager(String clusterName, String instanceName, InstanceType instanceType,
String zkAddress, HelixManagerStateListener stateListener, HelixManagerProperty helixManagerProperty)
Implement Cloud Instance Information (if necessary)
Helix has predefined a few fields in the interface of CloudInstanceInformation that are commonly used in participant. Users are free to define other fields in the instance metadata that they think are useful.
public interface CloudInstanceInformation {
/**
* Get the the value of a specific cloud instance field by name
* @return the value of the field
*/
String get(String key);
/**
* The enum contains all the required cloud instance field in Helix
*/
enum CloudInstanceField {
INSTANCE_NAME,
FAULT_DOMAIN,
INSTANCE_SET_NAME
}
}
Implement Cloud Instance Information Processor (if necessary)
Helix provides an interface to fetch and parse cloud instance information as follows. Helix makes the interface generic enough so that users may implement their own fetching and parsing logic with maximum freedom.
/**
* Generic interface to fetch and parse cloud instance information
*/
public interface CloudInstanceInformationProcessor<T extends Object> {
/**
* Get the raw cloud instance information
* @return raw cloud instance information
*/
List<T> fetchCloudInstanceInformation();
/**
* Parse the raw cloud instance information in responses and compose required cloud instance information
* @return required cloud instance information
*/
CloudInstanceInformation parseCloudInstanceInformation(List<T> responses);
}
Helix also implements an example processor for Azure in AzureCloudInstanceInformationProcessor. The implementation includes fetching and parsing Azure cloud instance information. The fetching function retrieves instance information from Azure AIMS, and the parsing function validates the response, and selects the fields needed for participant auto registration. If users would like to use Helix in an Azure environment, they do not need to implement it by themselves.
If users need to use Helix in another cloud environment, they can implement their own information processor. The implementation would be similar to Azure implementation, and the main difference would be in how to parse the response and retrieve interested fields.
Config Properly for Participant Auto Registration to Work
To make the participant auto registration work, users would need to make sure their cluster config is set properly. The most important one is the allowParticipantAutoJoin field in cluster config.
{
"id": "clusterName",
"listFields": {},
"mapFields": {},
"simpleFields": {
......
"allowParticipantAutoJoin": "true"
......
}
}
This field is used in participant manager logic as a prerequisite for participants to do auto registration. The detailed logic is shown in the following flow chart. The related code is in Participant Manager.
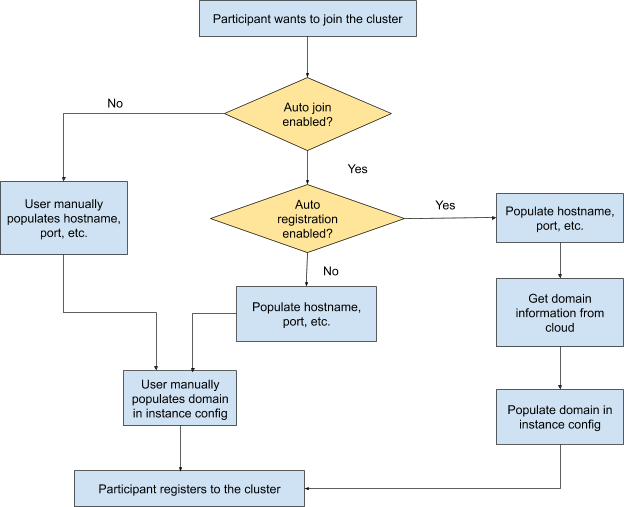
If the participant decides that it should do auto registration based on the config, it will first query cloud config and decide what environment it is in. Based on this information, the participant will call the corresponding cloud instance information processor. Then with all the information, especially the domain information, the participant can auto register to the cluster without any manual effort.