
Near-Realtime Rsync Replicated File System
Quick Demo
- This demo starts 3 instances with id's as
localhost_12001, localhost_12002, localhost_12003 - Each instance stores its files under
/tmp/<id>/filestore localhost_12001is designated as the master, andlocalhost_12002andlocalhost_12003are the slaves- Files written to the master are replicated to the slaves automatically. In this demo, a.txt and b.txt are written to
/tmp/localhost_12001/filestoreand they get replicated to other folders. - When the master is stopped,
localhost_12002is promoted to master. - The other slave
localhost_12003stops replicating fromlocalhost_12001and starts replicating from new masterlocalhost_12002 - Files written to new master
localhost_12002are replicated tolocalhost_12003 - In the end state of this quick demo,
localhost_12002is the master andlocalhost_12003is the slave. Manually create files under/tmp/localhost_12002/filestoreand see that appear in/tmp/localhost_12003/filestore - Ignore the interrupted exceptions on the console :-)
git clone https://git-wip-us.apache.org/repos/asf/helix.git
cd helix
git checkout tags/helix-1.0.2
cd recipes/rsync-replicated-file-system/
mvn clean install package -DskipTests
cd target/rsync-replicated-file-system-pkg/bin
chmod +x *
./quickdemo
Overview
There are many applications that require storage for storing large number of relatively small data files. Examples include media stores to store small videos, images, mail attachments etc. Each of these objects is typically kilobytes, often no larger than a few megabytes. An additional distinguishing feature of these use cases is that files are typically only added or deleted, rarely updated. When there are updates, they do not have any concurrency requirements.
These are much simpler requirements than what general purpose distributed file system have to satisfy; these would include concurrent access to files, random access for reads and updates, posix compliance, and others. To satisfy those requirements, general DFSs are also pretty complex that are expensive to build and maintain.
A different implementation of a distributed file system includes HDFS which is inspired by Google's GFS. This is one of the most widely used distributed file system that forms the main data storage platform for Hadoop. HDFS is primary aimed at processing very large data sets and distributes files across a cluster of commodity servers by splitting up files in fixed size chunks. HDFS is not particularly well suited for storing a very large number of relatively tiny files.
File Store
It's possible to build a vastly simpler system for the class of applications that have simpler requirements as we have pointed out.
- Large number of files but each file is relatively small
- Access is limited to create, delete and get entire files
- No updates to files that are already created (or it's feasible to delete the old file and create a new one)
We call this system a Partitioned File Store (PFS) to distinguish it from other distributed file systems. This system needs to provide the following features:
- CRD access to large number of small files
- Scalability: Files should be distributed across a large number of commodity servers based on the storage requirement
- Fault-tolerance: Each file should be replicated on multiple servers so that individual server failures do not reduce availability
- Elasticity: It should be possible to add capacity to the cluster easily
Apache Helix is a generic cluster management framework that makes it very easy to provide scalability, fault-tolerance and elasticity features. rsync can be easily used as a replication channel between servers so that each file gets replicated on multiple servers.
Design
High Level
- Partition the file system based on the file name
- At any time a single writer can write, we call this a master
- For redundancy, we need to have additional replicas called slave. Slaves can optionally serve reads
- Slave replicates data from the master
- When a master fails, a slave gets promoted to master
Transaction Log
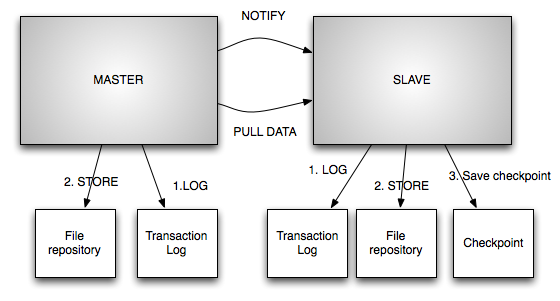
Every write on the master will result in creation/deletion of one or more files. In order to maintain timeline consistency slaves need to apply the changes in the same order To facilitate this, the master logs each transaction in a file and each transaction is associated with an 64 bit ID in which the 32 LSB represents a sequence number and MSB represents the generation number The sequence number gets incremented on every transaction and the generation is incremented when a new master is elected
Replication
Replication is required for slaves to keep up with changes on the master. Every time the slave applies a change it checkpoints the last applied transaction ID. During restarts, this allows the slave to pull changes from the last checkpointed ID. Similar to master, the slave logs each transaction to the transaction logs but instead of generating new transaction ID, it uses the same ID generated by the master.
Failover
When a master fails, a new slave will be promoted to master. If the previous master node is reachable, then the new master will flush all the changes from previous the master before taking up mastership. The new master will record the end transaction ID of the current generation and then start a new generation with sequence starting from 1. After this the master will begin accepting writes.
Rsync-based Solution
This application demonstrates a file store that uses rsync as the replication mechanism. One can envision a similar system where instead of using rsync, one can implement a custom solution to notify the slave of the changes and also provide an api to pull the change files.
Concepts
- file_store_dir: Root directory for the actual data files
- change_log_dir: The transaction logs are generated under this folder
- check_point_dir: The slave stores the check points ( last processed transaction) here
Master
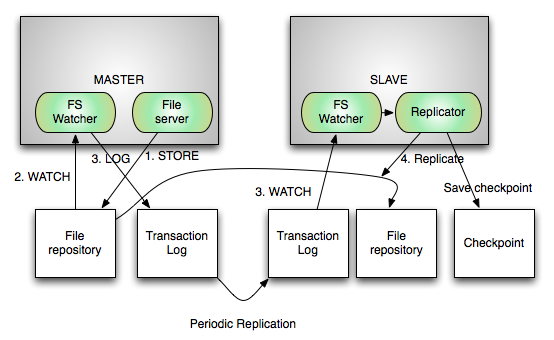
- File server: This component supports file uploads and downloads and writes the files to
file_store_dir. This is not included in this application. The idea is that most applications have different ways of implementing this component and have some associated business logic. It is not hard to come up with such a component if needed. - File store watcher: This component watches the
file_store_dirdirectory on the local file system for any changes and notifies the registered listeners of the changes - Change log generator: This registers as a listener of the file store watcher and on each notification logs the changes into a file under
change_log_dir
Slave
- File server: This component on the slave will only support reads
- Cluster state observer: Slave observes the cluster state and is able to know who is the current master
- Replicator: This has two subcomponents
- Periodic rsync of change log: This is a background process that periodically rsyncs the
change_log_dirof the master to its local directory - Change Log Watcher: This watches the
change_log_dirfor changes and notifies the registered listeners of the change - On demand rsync invoker: This is registered as a listener to change log watcher and on every change invokes rsync to sync only the changed file
- Periodic rsync of change log: This is a background process that periodically rsyncs the
Coordination
The coordination between nodes is done by Helix. Helix does the partition management and assigns the partition to multiple nodes based on the replication factor. It elects one the nodes as master and designates others as slaves. It provides notifications to each node in the form of state transitions (Offline to Slave, Slave to Master). It also provides notifications when there is change is cluster state. This allows the slave to stop replicating from current master and start replicating from new master.
In this application, we have only one partition but its very easy to extend it to support multiple partitions. By partitioning the file store, one can add new nodes and Helix will automatically re-distribute partitions among the nodes. To summarize, Helix provides partition management, fault tolerance and facilitates automated cluster expansion.