
CrushED (Crush-based rebalancer with Even Distribution)
Overview
Helix provides AutoRebalanceStrategy which is based on card dealing strategy. This strategy takes the current mapping as an input, and computes new mappings only for the partitions that need to be moved. This provides minimum partition movement, but the mapping is not deterministic, and moreover, fault-zone aware mapping (i.e. rack-aware partitioning) is not possible.
CRUSH-based partitioning scheme was implemented to provide fault-zone aware mapping and deterministic partition assignment. CrushRebalanceStrategy (and MultiRoundCrushRebalanceStrategy) algorithm uses pseudo-random partition placement to ensure consistent partition distribution. As the number of placed items (i.e partitions) approaches infinity, the distribution will be perfectly uniform. However, with a small number of placed items, especially for resources (i.e. databases) with a small number of partitions, the placement algorithm may result in fairly uneven partition distribution.
We want to provide a new rebalance strategy that provides a deterministic and fault-zone aware mapping while providing even partition distribution in all cases. In this document, we propose a hybrid algorithm that uses CRUSH, card dealing strategy, and consistent hashing to ensure both even distribution and minimal partition movement (while cluster topology remains the same). We call it CrushED (Crush w/ Even Distribution). Compared to CRUSH, CrushED results in a much more uniform distribution and minimal partition movements as long as topology remains the same, at the cost of additional run time computation.
Design
In addition to what we already achieved in CrushRebalanceStrategy, we have 2 high level goals :
- Even distribution.
- Minimize partition movements when instances go up/down.
CrushRebalanceStrategy has very small movement count, but the distribution is not optimal. MultiRoundCrushRebalanceStrategy was designed to solve this problem by running CRUSH multiple times on partition assignments that contribute to uneven mapping. However, due to potentially high number of rounds, computation cost is high, we observed significantly more partition movements when the cluster topology is changed.
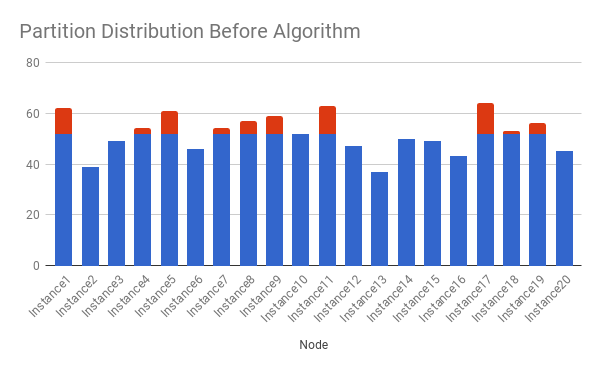
Since we have a good base strategy, CrushRebalanceStrategy, we built CrushEDRebalanceStrategy on top of it. Sample mapping of both strategies are as following. Note that blue parts remain unchanged before and after.
Before (CRUSH)
After (new strategy)
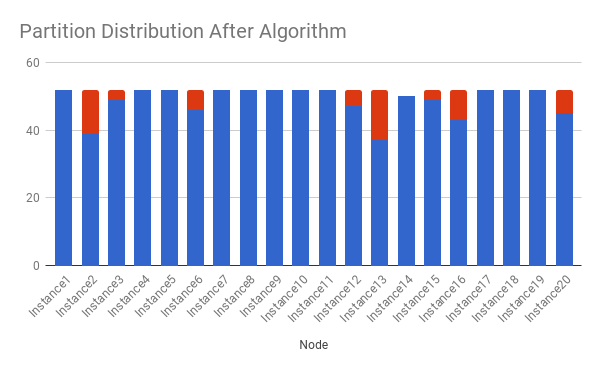
Since the problem is NP-hard. We are not expecting the best assignment. A greedy algorithm works good enough.
After we tried different designs, we found it's hard to achieve both goals (even distribution and fewer movements) using a single strategy. So we decided to apply a hybrid algorithm that finishes the work step by step.
Step 1, run CRUSH to get a base assignment.
The base assignment usually contains a certain number of uneven partitions(i.e. extra partitions above perfect distribution), so we need the following steps to re-distribute them.
Step 2, run a card dealing algorithm on the uneven parts.
Assign extra partitions to under-loaded nodes, using card dealing strategy. This algorithm is conceptually simple. The result ensures that all partitions are assigned to instances with minimum difference. When gauranteeing fault-zone safe assignment, our greedy algorithm may not be able to calculate possible results because of fault-zone conflict.
Example of assignments after step 2,
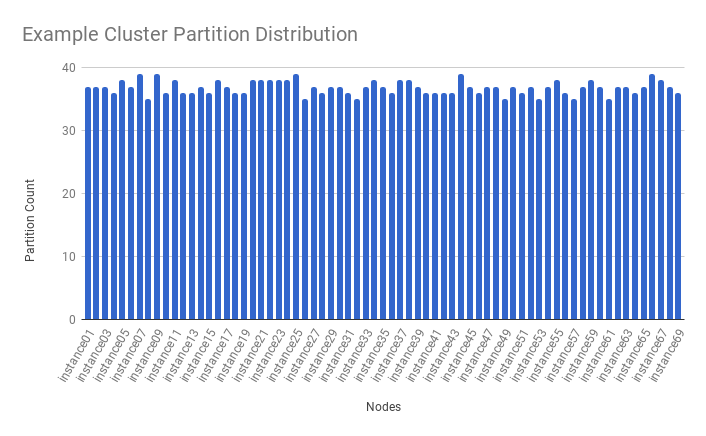
Step 3, Shuffle partitions' preference lists.
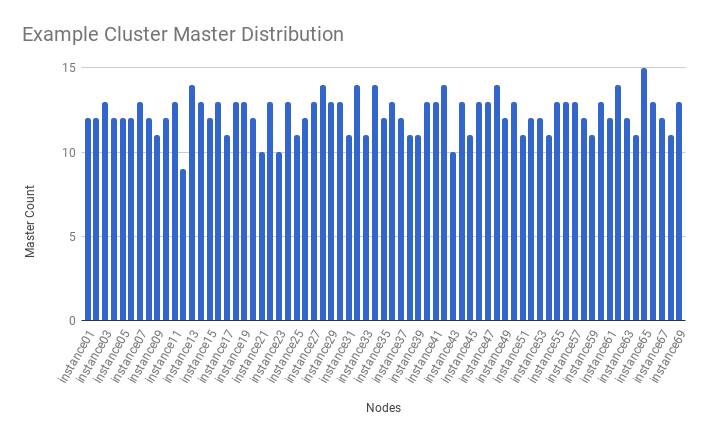
State assignments (i.e. Master, Slave, Online, Offline, etc) are made according to preflist, ordered node. When using randomly ordered lists, State assignment is also random, and it may result in uneven state distribution. To resolve this issue, CrushED assigns scores to nodes as it computes pref list, to give all nodes equal chances in appearing at the top of the pref list. This operation results in a much more even state distribution.
Example of master distribution before step 3,
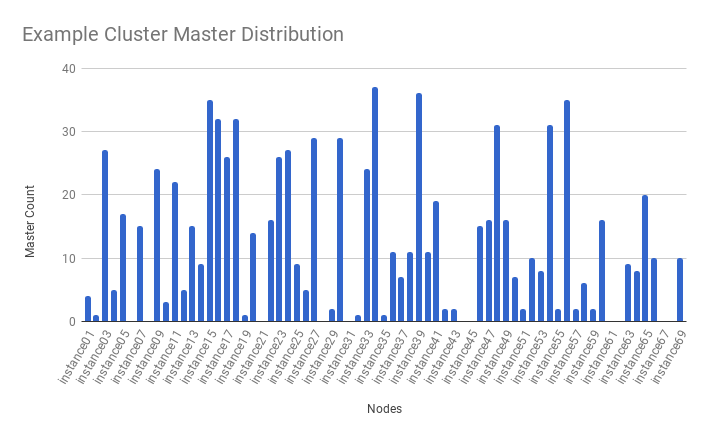
Example of master distribution after step 3,
Step 4, re-calculate the assignment for the partitions on temporarily disabled nodes using a consistent hashing algorithm.
Consistent hashing ensures minimize partition movement.
Note that the first 3 steps are using full node list, regardless of disabled or offline nodes. So the assignment will be stable even the algorithm contains random factors such hashCode. Then step 4 ensures all the disabled nodes are handled correctly without causing huge partition movements.
Pseudocode of above algorithm is as follows :
Pseudo Code
// Round 1: Calculate mapping using the base strategy.
// Note to use all nodes for minimizing the influence of live node changes.
origPartitionMap = getBaseRebalanceStrategy().computePartitionAssignment(allNodes, clusterData);
// Transform current assignment to instance->partitions map, and get total partitions
nodeToPartitionMap = convertMap(origPartitionMap);
// Round 2: Rebalance mapping using card dealing algorithm.
Topology allNodeTopo = new Topology(allNodes, clusterData);
cardDealer.computeMapping(allNodeTopo, nodeToPartitionMap);
// Since states are assigned according to preference list order, shuffle preference list for even states distribution.
shufflePreferenceList(nodeToPartitionMap);
// Round 3: Re-mapping the partitions on non-live nodes using consistent hashing for reducing movement.
// Consistent hashing ensures minimum movements when nodes are disabled unexpectedly.
if (!liveNodes.containsAll(allNodes)) {
Topology liveNodeTopo = new Topology(liveNodes, clusterData);
hashPlacement.computeMapping(liveNodeTopo, nodeToPartitionMap);
}
if (!nodeToPartitionMap.isEmpty()) {
// Round 2 and 3 is done successfully
return convertMap(nodeToPartitionMap);
} else {
return getBaseRebalanceStrategy().computePartitionAssignment(liveNodes, clusterData);
}
Maximum uneven partition assignment using CrushED
Helix cluster typically manages 1 or more resources (i.e. databases). For each resource, CrushED makes the best effort to ensure the partition count difference is at most 1 across all the instances. Assuming such assignment is possible considering fault-zone configuration, the worst partition distribution happens when all one off partitions are located in one node. So N resources in a cluster can theoretically have their extra partitions in one node, so the node will have N additional partitions in total. Thus, the maximum difference between the most heavily loaded node and the least is the number of resources in a cluster.
Experiment
We tested CrushED by simulating real production cluster topology data. And we tested multiple scenarios:
- Distribution based on cluster topology.
- Disabling hosts to simulate hosts down.
- Adding hosts to simulate expansion.
- Rolling upgrade.
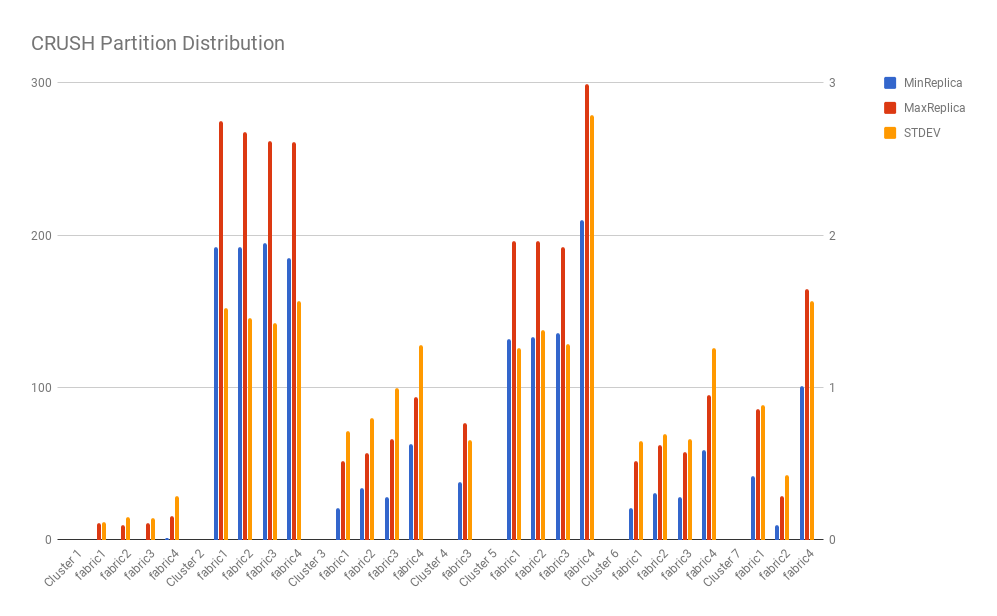
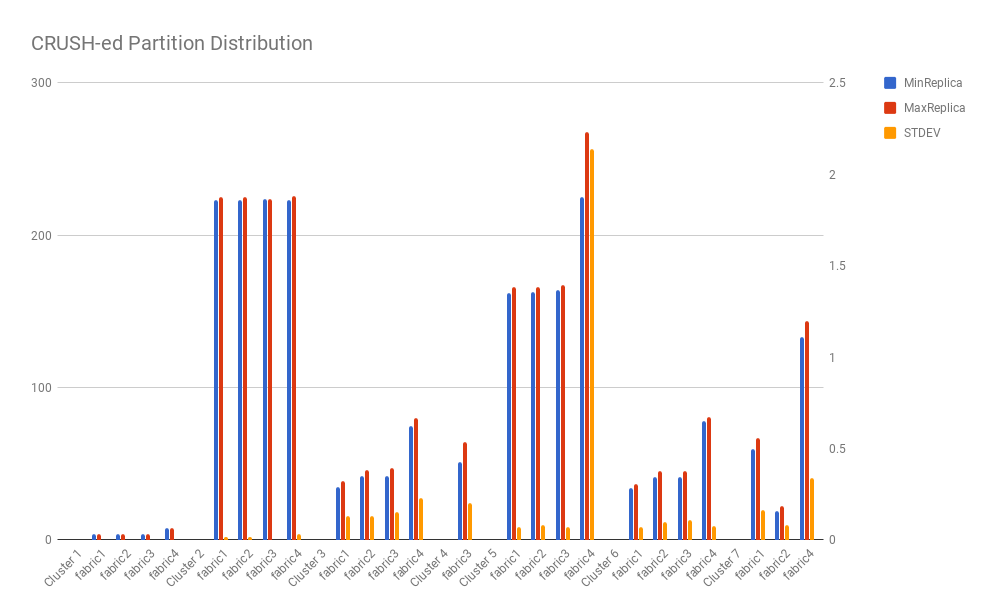
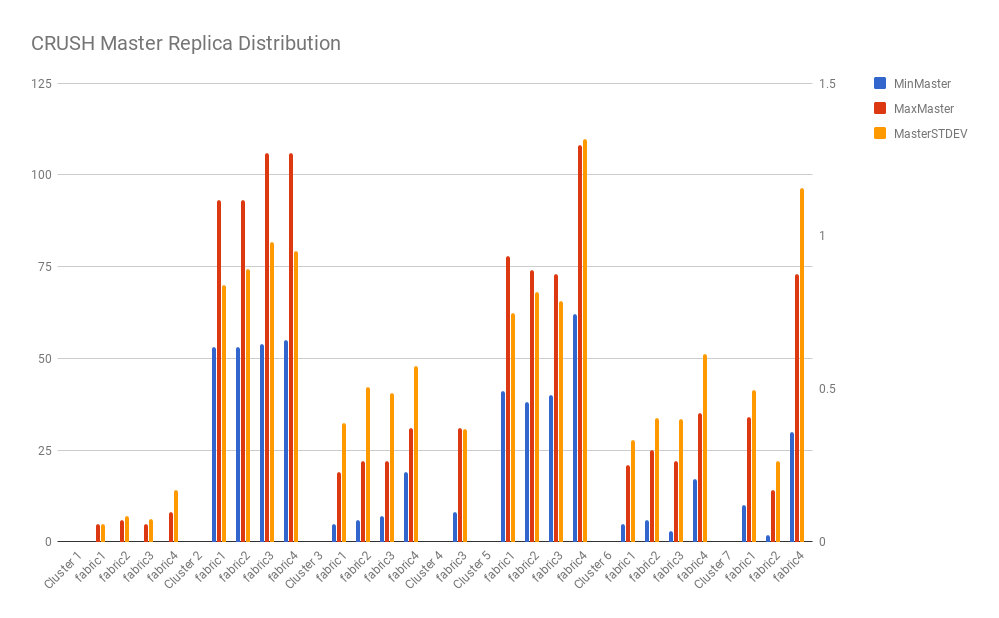
All results show that CrushED generates more uniform global distribution compared with CRUSH.
Moreover, partition movements in most scenarios are minimized. When topology changes (i.e. cluster expansion), there can be significantly more partition movements, but we can control the impact by using State Transition Throttling feature.
Partition Distribution
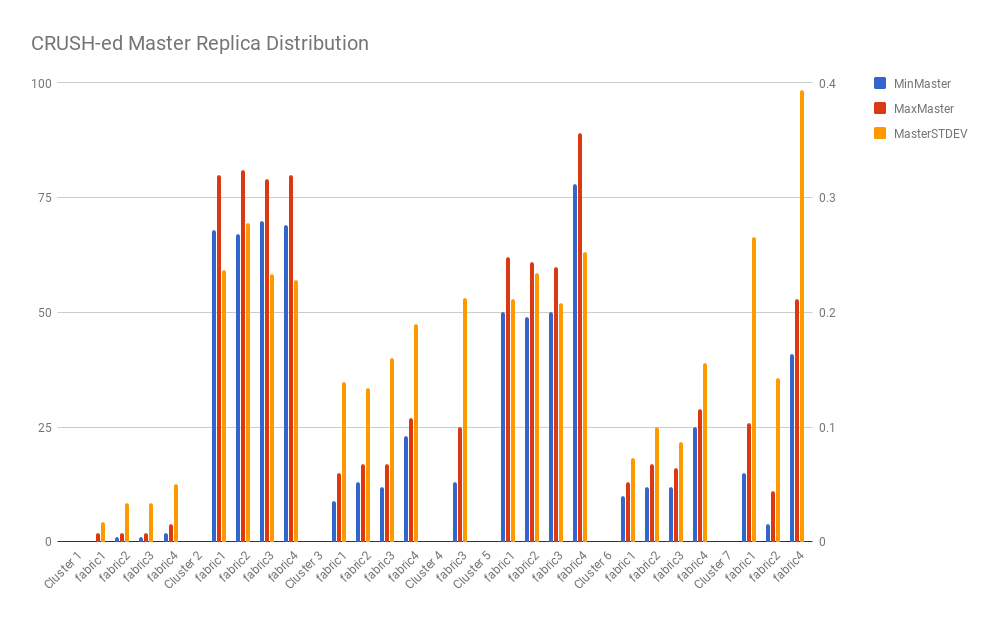
Following charts demonstrate the worst cases (min load vs. max load) and STDEVs of partition/master distributions from some sample clusters data.
If we measure the improvement by STDEV, CrushED improves the partition distribution evenness by 87% on average compared with CRUSH. And for state assignment (i.e. Mastership assignment) the evenness improvement is 68% on average.
Disabling Nodes
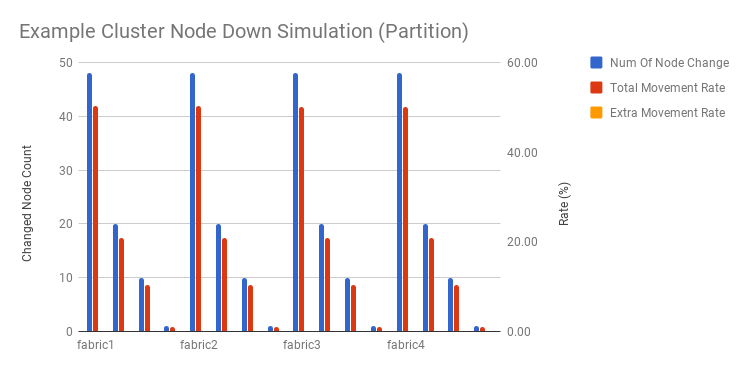
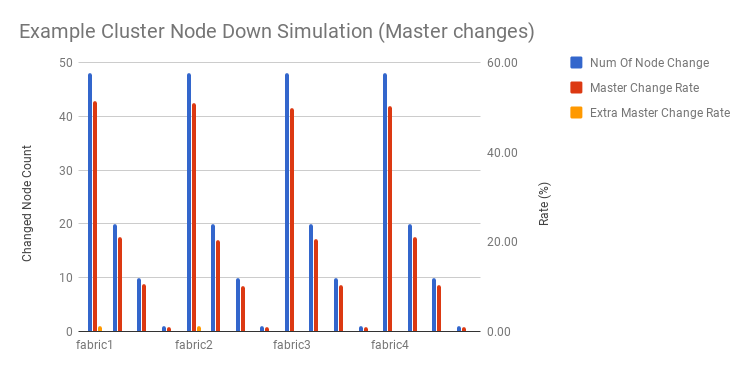
When nodes are offline or disabled, CrushED will re-assign the partitions to other live nodes. The algorithm move only the necessary partitions.
We simulated disabling nodes, and measured partition movement changes and mastership changes. We also used the expected movement (the partitions/masters count on the disabled nodes) as a baseline to measure extra movements.
The results show that movement is highly correlated to the number of disabled nodes, and extra movements are minor (in most cases 0 movements).
Note that Rate in this document is the changed number / total partition or master count.
Rolling upgrade
Rolling upgrade is different from disabling nodes. Since nodes are reset one by one, in this test we assume the difference could be 2 nodes in maximum (for example, upgrading Node A then upgrading Node B).
In this case, movements are still minimized. Even in the worst case scenario, extra partition movements and mastership changes are still close to 0%.
Note that in real production clusters, we can completely avoid partition movements while doing rolling upgrade, by enabling Delayed Rebalancing.
Adding Nodes
Adding nodes (i.e. cluster expansion) changes topology. CrushED uses card dealing strategy to provide even distribution, so when topology changes, there are a lot of additional partition movements than CRUSH.
Note that the extra change rate is not correlated with the number of additional nodes. So our recommendation is finishing expansion in one operation so as to do only one partition shuffling.
Algorithm Performance
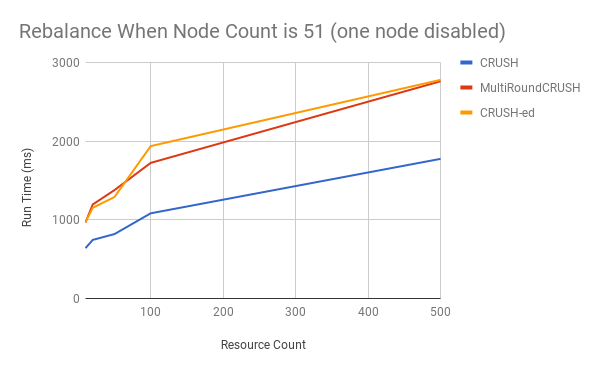
We compared CrushED with CRUSH algorithms using different instance numbers. The tests are executed multiple times and we recorded median computation time.
CrushED does not cost much additional computation time for regular rebalancing. In some of the worst cases, 30% more runtime was observed, compared with CRUSH, but it is quicker than MultiRoundCRUSH.
However, when there are down nodes since CrushED needs to run an additional consistent hashing based re-distribution, the computation time will be much longer. In some cases, we saw more than 3 times compared to CRUSH.
With some performance improvements, such as using cache to avoid duplicate calculation, we achieved to greatly reduce CrushED's running time. According to our experiment, it is now close to MultiRound CRUSH.
Conclusion
CrushED achieves more uniform distribution compared with CRUSH at the cost of higher rebalance computation and more partition movement when the cluster topology changes.
Simple User Guide
- Ensure the resouce is using FULL_AUTO mode.
- Set rebalance strategy to be “org.apache.helix.controller.rebalancer.strategy.CrushEdRebalanceStrategy”.
- Expect more partition movement on topology changes when using the new strategy.
IdeaState SimpleFields Example
HELIX_ENABLED : "true"
IDEAL\_STATE\_MODE : "AUTO_REBALANCE"
REBALANCE\_MODE : "FULL\_AUTO"
REBALANCE_STRATEGY : "org.apache.helix.controller.rebalancer.strategy.CrushRebalanceStrategy"
MIN\_ACTIVE\_REPLICAS : "0"
NUM_PARTITIONS : "64"
REBALANCER\_CLASS\_NAME : "org.apache.helix.controller.rebalancer.DelayedAutoRebalancer"
REPLICAS : "1"
STATE\_MODEL\_DEF_REF : "LeaderStandby"